Book notes: Building Microservices - Second edition
Book notes on "Building Microservices: Designing Fine-Grained Systems" by Sam Newman

These are my notes on Building Microservices: Designing Fine-Grained Systems by Sam Newman.
When an author lists more drawbacks thatn benefits (nine vs six), you know he knows what he is talking about.
Key Insights
- Independent deployability is key.
- Clear, stable service boundaries.
- Smaller teams working on smaller codebases tend to be more productive.
| Benefits | Pain Points |
|---|---|
| Tech heterogeneity | Tech overload |
| Robustness | Latency |
| Scalability | Data Consistency |
| Easy of deployment | Dev experience |
| Org alignment | Cost |
| Composability | Monitoring and troubleshooting |
| Reporting | |
| Security | |
| Testing |
- When to avoid:
- Start ups:
- Because no stable service boundaries.
- Small teams.
- SW deployed by customers, due to operation burden.
- Start ups:
- Keep your middleware dumb, and keep the smarts in the endpoints.
- Prefer to put into an event what you would be happy to share via an API.
- Ideal technology should:
- Make backwards compatibility easy.
- Make interfaces explicit.
- Keep your APIs technology-agnostic.
- Make services simple for consumers.
- Hide internal implementation details.
- Communication:
- RPC:
- gRPC good, other bad.
- Use when good deal of control of client and server.
- REST:
- Sensible default choice.
- Good for external API: wide support + caching.
- HATEOAS: No practical advantage.
- GraphQL:
- Dynamic queries can cause stability issues similar to a big/slow/resource intensive SQL query affecting the whole system.
- CDN caching more difficult.
- Write requests are awkward.
- Message brokers:
- What any given broker technology means by guaranteed delivery can vary. Read the documentation very carefully.
- Pay really careful attention to how exactly once delivery is implemented (if it is).
- Even better, expect duplicates.
- RPC:
- Author still a fan of XML.
- Client libraries should be created by team other than the one that owns the server API.
- Sagas:
- Saga gives enough information to reason about what state it is in.
- Sagas assume the underlying components are reliable as it does not deal with technical failures (5xx, timeouts).
- General rule:
- If a team owns the implementation of the entire saga: orchestration.
- If multiple teams: choreographed.
- We want to build artifacts once and only once, and use them for all deployments.
- Source code organization:
- Multirepo:
- If you are constantly making changes across multiple services, your microservices boundaries are wrong.
- Monorepo:
- Ease changes in multiple services:
- Atomic commits (but not atomic deployments).
- Needs load of tooling:
- Ease changes in multiple services:
- Per team monorepo.
- Multirepo:
- 3 services per dev is not an uncommon ratio.
- The smarter the PaaS try to be, the more they go wrong.
- If you need to do a lot of fine tuning around resources available to your functions, then FaaS is not the best option.
- Explore FaaS before Kubernetes.
- Future: Kubernetes hidden under a more developer friendly experience.
- If your teams work independently, it follows that they should be able to test independently:
- If also follows that they should own their test environments.
- It is a reason against end-to-end tests.
- Contract testing and consumer-driven contracts:
- Pair consumer and producer team members to write them.
- Make existing communication channels more explicit.
- Pact Broker.
- Spring Cloud Contract. Only JVM.
- Monitoring:
- Log aggregation:
- Avoid log forwarding agents reformatting the logs. Make services log in the right format.
- Metrics aggregation:
- Look for a product that is built with high cardinality in mind, so you can attach more metadata/tags to the metrics.
- Distributed tracing:
- Pick a tool that supports OpenTelemetry.
- Semantic monitoring:
- Are we selling “as usual”?
- Implemented with:
- Real user monitoring: In the past.
- Synthetic transactions: Catch issues before clients are aware.
- Be sceptical of ML/AI.
- Log aggregation:
- Good alert:
- Relevant.
- Unique.
- Timely.
- Prioritized.
- Understandable.
- Diagnostic: clear what is wrong.
- Advisory: help understand what actions to take.
- Focusing.
- Standardization:
- Make it easy to do the right thing.
- You are only as secure as your least secure aspect.
- Credentials of users and operators are often the weakest point of our system:
- In 2020, 80% of hacks due to it.
- Cost of any security implementation should be justified by your threat model.
- Failure is everywhere:
- Spend less time trying to stop the inevitable and more dealing with it gracefully.
- Root cause analysis: it is surprising how often we want that root cause to be a human.
- CQRS: one of the hardest forms of scaling.
- The ideal number of places to cache is zero.
- When customizing a product built by someone else, you have to work in their world.
- One experience, one backend for frontend (BFF).
- Collective ownership can allow for more standardization, hence easier to move people/work around.
- The biggest cost to working efficiently at scale is the need of coordination.
- Coming up with a vision without considering how your staff will feel about it and without considering what capabilities they have is likely to lead to a bad place.
- Architecture is what happens, not what is planned.
- Make Product Manager accountable for the technical quality of the system.
TOC
Part I - Foundation
Chapter 1 - What are Microservices?
- Independent deployability is key.
- Clear, stable service boundaries.
- Monoliths:
- Single-process monolith.
- Modular monolith.
- Distributed monolith.
- Tech that enable microservices:
- Log aggregation and distributed tracing.
- Containers and Kubernetes.
- Streaming.
- Public Cloud and Serverless.
- Smaller teams working on smaller codebases tend to be more productive.
| Benefits | Pain Points |
|---|---|
| Tech heterogeneity | Tech overload |
| Robustness | Latency |
| Scalability | Data Consistency |
| Easy of deployment | Dev experience |
| Org alignment | Cost |
| Composability | Monitoring and troubleshooting |
| Reporting | |
| Security | |
| Testing |
- When to avoid:
- Start ups:
- Because no stable service boundaries.
- Small teams.
- SW deployed by customers, due to operation burden.
- Start ups:
Chapter 2 - How to Model Microservices
- Boundaries:
- Information hiding.
- Strong cohesion:
- Code that changes together, stays together.
- Low coupling.
- Types of coupling, from low to high:
- Domain coupling:
- Unavoidable: one service calling another.
- Beware of one service talking to too many downstream services:
- Too much logic centralized.
- God “class”.
- Pass-through coupling:
- One service passes data to another purely because the data is needed further downstream.
- Fix by:
- Bypass the intermediary:
- Increase the domain coupling of calling service.
- Required information to become part of the intermediary contract:
- Intermediary to collect all/part of that data.
- Intermediary to treat required information as a blob:
- The Clojure way!
- Bypass the intermediary:
- Common coupling:
- Two services using the same data.
- Okish for reference data ( low change, read only).
- Service that are thin wrappers around CRUD, is a sign of weak cohesion and high coupling.
- Content coupling:
- Upstream service reaches into the internals of a downstream service and changes its internal state.
- Other services touching your DB directly.
- Domain coupling:
- To model:
- Mainly, use DDD:
- Both aggregates and bounded context give us the unit of cohesion with well defined interfaces: candidates for microservices.
- Coarser-grained bounded context can contain/hide other bounded context.
- Event Storming.
- Other forces:
- Volatility: things that change frequently should go into their own service.
- Data: PII/PCI.
- Technology: use the right tool for the job.
- Organizational: Conway’s law.
- Mainly, use DDD:
- Onion architecture: it has lots of layers and makes you cry when you have to cut through it.
Chapter 3 - Splitting the Monolith
Skipped. See book notes on Monolith to Microservices: Evolutionary Patterns to Transform Your Monolith.
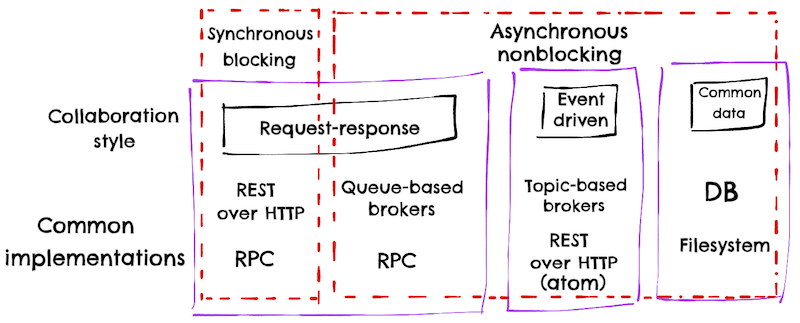
Chapter 4 - Microservices Communication Styles
- When you buy into specific tech choice, you are buying into a set of ideas and constraints that come with it.
- Sync blocking: beware of long call chains.
- Common data:
- Large volumes.
- Universal.
- High latency.
- Keep your middleware dumb, and keep the smarts in the endpoints.
- Prefer to put into an event what you would be happy to share via an API.
Part II - Implementation
Chapter 5 - Implementing Microservices Communication
- Ideal technology should:
- Make backwards compatibility easy.
- Make interfaces explicit.
- Keep your APIs technology-agnostic.
- Make services simple for consumers.
- Hide internal implementation details.
- Choices:
- RPC:
- gRPC good, other bad.
- Use when good deal of control of client and server.
- REST:
- Open API concern: a spec used for documenting now being used for a more explicit contract.
- Lot more complex than protobuf.
- Less performance than gRPC.
- HTTP/3: based on QUIC, less overhead than TPC.
- Sensible default choice.
- Good for external API: wide support + caching.
- HATEOAS:
- Many of the ideas in REST are predicated on creating distributed hypermedia systems, and this isn’t what most people end up building.
- More chatty.
- No practical advantage.
- GraphQL:
- Dynamic queries can cause stability issues similar to a big/slow/resource intensive SQL query affecting the whole system.
- CDN caching more difficult.
- Write requests are awkward.
- Message brokers:
- What any given broker technology means by guaranteed delivery can vary. Read the documentation very carefully.
- Pay really careful attention to how exactly once delivery is implemented (if it is).
- Even better, expect duplicates.
- RPC:
- Serialization formats:
- Author still a fan of XML.
- Use schemas to catch structural breakages.
- Avoid breaking changes:
- Just add, never remove.
- Tolerant reader.
- Explicit interfaces:
- Breaking changes:
- Lockstep deployments:
- Avoid.
- More palatable if service + all consumers owned by the same team.
- Coexists incompatible microservices versions:
- Use sparingly and for short periods of time.
- Emulate the old interface:
- Preferred approach.
- Author torn between encoding versions in urls (simpler, obvious) or specify in header (less coupling).
- Social contract:
- How breaking changes will be notified?
- How they will be agreed upon?
- Who will update the consumers?
- How long before old endpoint is removed?
- Lockstep deployments:
- If you are using libraries for code reuse across microservices boundaries, you have to accept that multiple versions of that library will be out there.
- Client libraries should be created by team other than the one that owns the server API:
- To avoid tightly coupled.
- Service discovery:
- DNS:
- Slow to propagate changes.
- Okish with a load balancer.
- Dynamic service registries:
- Avoid Zookeeper.
- Consul: good, specially if you need Vault also.
- etcd/kubernetes.
- DNS:
- When using an API gateway or service mesh, it is essential that their behaviour is generic, agnostic of specific microservices.
- In API gateway, avoid:
- Call aggregation.
- Protocol rewriting.
- Use between your microservices.
- BizOps.
Chapter 6 - Workflow
- Sagas does not give atomicity in ACID terms:
- Saga gives enough information to reason about what state it is in.
- Saga failure mode:
- Sagas assume the underlying components are reliable as it does not deal with technical failures (5xx, timeouts).
- Backwards recovery: compensating transactions.
- Forward recovery: retry and keep processing.
- Orchestrated sagas:
- One coordinator.
- Easy to understand: one place to look at how a process work.
- High coupling.
- Risk of “god” service and anemic ones:
- Avoid by having different services play the orchestrator role for different flows.
- Choreographed sagas:
- More decoupled.
- harder to understand the process and the saga state.
- Saga state:
- Events should have a correlationID or sagaID.
- A process consumes all events to show the actual state.
- General rule:
- If a team owns the implementation of the entire saga: orchestration.
- If multiple teams: choreographed.
Chapter 7 - Build
- We want to build artifacts once and only once, and use them for all deployments.
- Source code organization:
- One giant repo, one giant build:
- Avoid.
- Multirepo:
- Hard to work with several services at the same time.
- If you are constantly making changes across multiple services, your microservices boundaries are wrong.
- Most straightforward.
- Monorepo:
- Ease:
- Fine grained code reuse.
- Changes in multiple services:
- Atomic commits (but not atomic deployments).
- Needs load of tooling:
- Ease:
- Per team monorepo.
- One giant repo, one giant build:
Chapter 8 - Deployment
- Principles of microservices deployment:
- Isolated execution.
- Focus on automation:
- Aim for self-service.
- 3 services per dev is not an uncommon ratio.
- Infrastructure as code:
- Zero-downtime deployment:
- Avoid coordination.
- Desired state management:
- Declarative state.
- Platform automatically makes changes to arrive to the desired state.
- Kubernetes / Nomad.
- GitOps: Flux.
- Deployment options:
- Physical machine.
- Virtual machine:
- Stricter isolation than containers.
- Containers:
- More lightweight than virtual machines.
- Application containers.
- Platform as a service (PaaS):
- When PaaS solutions work well for your context, they work very well indeed.
- The smarter the PaaS try to be, the more they go wrong.
- Function as a Service (FaaS):
- If you need to do a lot of fine tuning around resources available to your functions, then FaaS is not the best option.
- Azure Durable Functions.
- Cold start is optimized in most platforms.
- One function per microservice or per aggregate:
- Avoid more fine-grained.
- Explore FaaS before Kubernetes.
- Kubernetes has limited multitenancy capabilities:
- Use OpenShift.
- Use federated model: multiple Kubernetes clusters with a layer on top.
- Knative aims to provide FaaS-style workflows to developers:
- Risky to adopt.
- Future: Kubernetes hidden under a more developer friendly experience.
- Progressive delivery:
- Separate deployment from release.
- Blue/Green deployments.
- Feature toggles.
- Canary releases:
- Parallel run: send to old and new and compare.
Chapter 9 - Testing
- Who owns an end-to-end test suite?
- Everybody / nobody.
- Dedicated team: this can be disastrous.
- Split suite and assign subsets to teams.
Actively remove tests that are no longer needed.
Why not use a version number for the whole system? Now you have 2.1.0 problems. Brandom Byars
If your teams work independently, it follows that they should be able to test independently:
- If also follows that they should own their test environments.
- It is a reason against end-to-end tests.
- Contract testing and consumer-driven contracts:
- Pair consumer and producer team members to write them.
- Make existing communication channels more explicit.
- Pact Broker.
- Spring Cloud Contract. Only JVM.
Chapter 10 - From Monitoring to Observability
- Observability: the extent to which you can understand the internal state of the system from external outputs.
- Monitoring and observability system are production systems.
- Building blocks:
- Log aggregation:
- Prerequisite for microservices.
- Pick a common format.
- Avoid log forwarding agents reformatting the logs. Make services log in the right format.
- Log correlation ID.
- Careful with timestamps and clock skew:
- Tracing does not have this issue.
- Metrics aggregation:
- Look for a product that is built with high cardinality in mind, so you can attach more metadata/tags to the metrics.
- Prometheus is low-cardinality.
- HoneyComb or LightSteps.
- Distributed tracing:
- Pick a tool that supports OpenTelemetry.
- Are we doing ok?
- SLA.
- SLO: at the team level.
- SLI: indicator-data to know if we are meeting a SLO.
- Error budgets.
- Alerting:
- Biggest question: Should this problem cause someone to be woken up at 3am?
- Avoid overalerting.
- Good alert:
- Relevant.
- Unique.
- Timely.
- Prioritized.
- Understandable.
- Diagnostic: clear what is wrong.
- Advisory: help understand what actions to take.
- Focusing.
- Semantic monitoring:
- Are we selling “as usual”?
- Are users login as usual?
- Implemented with:
- Real user monitoring:
- In the past.
- Noisy.
- Synthetic transactions:
- Catch issues before clients are aware.
- Real user monitoring:
- Testing in production:
- Synthetic transactions.
- A/B testing.
- Canary releases.
- Parallel run.
- Smoke test.
- Chaos engineering.
- Log aggregation:
- Standardization:
- Important in monitoring and observability.
- Make it easy to do the right thing.
- Select tools that:
- Democratic: everybody can use them.
- Easy to integrate: OpenTelemetry.
- Provide temporal, relative, relational and proportional context.
- Realtime.
- Suitable for your scale.
- Be sceptical of ML/AI.
Chapter 11 - Security
- You are only as secure as your least secure aspect.
- Core principles:
- Least privilege.
- Defense in depth:
- Multiple protections.
- Microservices provide more defense in depth than monoliths as:
- They have smaller scope.
- Can be segmented in networks.
- Automation:
- Recover.
- Rotate keys.
- Five functions of Cybersecurity:
- Identify potential attackers, their targets are where you are most vulnerable:
- As human beings, we are quite bad at understanding risks.
- Threat modeling:
- Focus on the whole system, not a subset.
- Protect.
- Detect.
- Respond.
- Recover.
- Identify potential attackers, their targets are where you are most vulnerable:
- Foundations of application security:
- Credentials:
- Credentials of users and operators are often the weakest point of our system:
- In 2020, 80% of hacks due to it.
- Troy Hunt, Passwords evolved:
- Use password managers.
- Avoid complex password rules.
- Avoid mandated regular password changes.
- git-secret and gitleaks.
- Credentials of users and operators are often the weakest point of our system:
- Patching:
- Backups.
- Rebuilds:
- Including restoration of backed up data.
- Credentials:
- Cost of any security implementation should be justified by your threat model.
- Data in transit:
- Server identity: HTTPS.
- Client identity:
- Mutual TLS.
- API keys.
- Visibility of data: HTTPS.
- Manipulation of data:
- HTTPS.
- HMAC.
- Data at rest:
- Where do you store the encryption keys?
- Do fine-grained authorization in service. It is ok for coarse-grained in the gateway.
- Gateway generating a JWT per request.
- Agile Application Security by Laure Bell.
Chapter 12 - Resilience
- Resilience:
- Robustness:
- The ability to absorb expected perturbation.
- As we increase robustness, we increase complexity.
- Rebound:
- Ability to recover after a traumatic event.
- Graceful extensibility:
- How well we deal with a situation that is unexpected.
- Flatter orgs will often be better prepared.
- Optimizations can increase brittleness.
- Sustained adaptability:
- Ability to continually adapt to changing envs, stakeholders and demands.
- Requires a holistic view of the system.
- Share information freely on an incident.
- Culture to find time to learn from incident.
- Robustness:
- Failure is everywhere:
- Spend less time trying to stop the inevitable and more dealing with it gracefully.
- Responding very slowly is one of the worst failure modes you can experience.
- CP (from CAP theorem) systems can’t fix all your problems, specially if you keep records of the real world.
- Blame:
- Root cause analysis: it is surprising how often we want that root cause to be a human.
- If it is true that one person making a mistake can really bring an entire telco to its knees, you’d think that would say more about the telco than the individual.
Chapter 13 - Scaling
- Four axes:
- Vertical scaling:
- In a public cloud provider, is very fast to apply.
- Little risk.
- Does not improve robustness.
- Horizontal duplication:
- It does improve robustness.
- Data partitioning:
- It does not improve robustness.
- Functional decomposition:
- It does improve robustness.
- Can choose tech most appropriate to the microservice load.
- Vertical scaling:
- CQRS: one of the hardest forms of scaling.
- Caching:
- Improves robustness.
- Client-side:
- Main issue is invalidation and consistency.
- Better latency.
- Server-side:
- Main issue is that clients still need to make a network trip.
- Latency improved for all clients.
- Server to return TTL.
- Conditional GET (ETag).
- Notification (pub/sub):
- Consider adding a heartbeat.
- The ideal number of places to cache is zero.
- At certain scaling points, you will need to rearchitect.
Part III - People
Chapter 14 - User Interfaces
- Traditional reasons for dedicated FE teams:
- Scarcity of specialist:
- Share between teams:
- Do the hard bits and teach the team to do the easy ones.
- Enabling teams.
- Share between teams:
- UI consistency:
- Enabling teams.
- Design System.
- Technical challenge:
- Monolith FE.
- Micro FE:
- Key problem: unlikely that 1 micro FE == 1 microservice, so micro FE ends up making multiple API calls to multiple BE services.
- 2 types:
- Page-based decomposition:
- We’ve lost a lot by automatically assuming that a web-based UI means a single-page app.
- Forward traffic to microservice/microFE depending on url.
- Widget-based decomposition:
- Needs an assembly layer to pull the parts together.
- Options:
- Iframes: issues with comms between widgets.
- Server-side templating.
- Dynamically inserted by the client.
- Issues:
- Dependencies:
- Great to upgrade one widget dependencies at a time.
- Duplication of libraries to download.
- Communication using custom events:
- Same as event-driven communication patterns.
- Dependencies:
- Page-based decomposition:
- Central aggregating gateway:
- Often the central aggregating gateway does so much that ends up being owned by a dedicated team:
- Potential contention and bottleneck.
- When customizing a product built by someone else, you have to work in their world.
- Strongly advise against using filtering and aggregation capabilities of dedicated gateway API.
- Often the central aggregating gateway does so much that ends up being owned by a dedicated team:
- Backend for frontend (BFF):
- Like (3) but one BFF per FE.
- FE and its BFF owned by same team and very coupled.
- One experience, one BFF.
- Consider BFF for external parties as a way to isolation APIs.
- GraphQL.
- Scarcity of specialist:
Chapter 15 - Organizational Structures
- The biggest cost to working efficiently at scale is the need of coordination.
- Conways law, team API, platform team, enabling teams: Team Topologies.
- Automation is key.
- Dunbar numbers.
- Strong ownership can allow for more local variation than collective ownership.
- Collective ownership can allow for more standardization, hence easier to move people/work around.
- When creating an internal framework, it all starts with the best intentions.
- Avoid internal framework unless you’ve exhausted your other options.
- Do code reviews promptly: pair programming FTW!
- Coming up with a vision without considering how your staff will feel about it and without considering what capabilities they have is likely to lead to a bad place.
Chapter 16 - The Evolutionary Architect
- Architects and engineers have a rigor and discipline we could only dream of.
- Many forms of IT certification are worthless, as we know little about what “good” looks like.
- SW architects should focus on helping create a framework in which the right systems can emerge and continue to grow as we learn more.
- SW arch as a town planner. (Same analogy as in Elements of Clojure).
- Architecture is what happens, not what is planned.
- Habitability: is the characteristic of source code that enables programmers coming to the code later in its life to understand its construction and intentions and to change it comfortably and confidently.
- Strategic goals -> Technical vision -> Principles -> Practices.
- Architects as an enabling team:
- 2-3 full time architects plus tech leads.
- Make Product Manager accountable for the technical quality of the system.
- Key things to standardize:
- Monitoring.
- Interfaces between microservices.
- Architectural safety (error codes, circuit breakers, …).
- Governance:
- Group activity, mostly people executing the work being governed.
- Examples.
- Microservices templates.