Where TDD falls short, find yourself a good REPL
TDD is an awesome workflow, but not for everything.
Test-Driven Development (TDD) is by far the best workflow to get things done.
It has but one little problem: before you start doing, you need to understand and learn what must be done.

The TDD workflow by itself does not help with the learning, but as most of our work is about changing existing code, the byproduct of TDD – tests –, can help us to learn how things are working now.
Unfortunately tests usually do not help to understand why things are the way they are.
For novel work, neither the TDD workflow nor the existing test suite is of any use. For novel work, we need to use other sources and tools to acquire that knowledge.
We can split novel work into:
- New business logic.
- Unfamiliar libraries and frameworks.
- Side effects.
New business logic
To learn about the new business logic to implement, you cannot start by writing tests, but neither can you start writing production code.
You will need to sit down with your business expert counterpart.
As you implement the new logic, you will need clarification, you will find edge cases, you will discover contradictions with the existing logic, … all of which will require again of the business expert input, creating a loop between doing and learning:
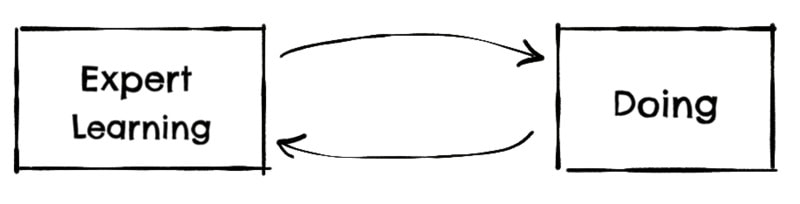
To make this feedback loop fast, the on-site customer practice may help you.
But your business expert will not have all the answers, and as part of the learning, you will together explore what is possible, what data would be required, what third parties should we integrate, what edge cases we will need to cover, …
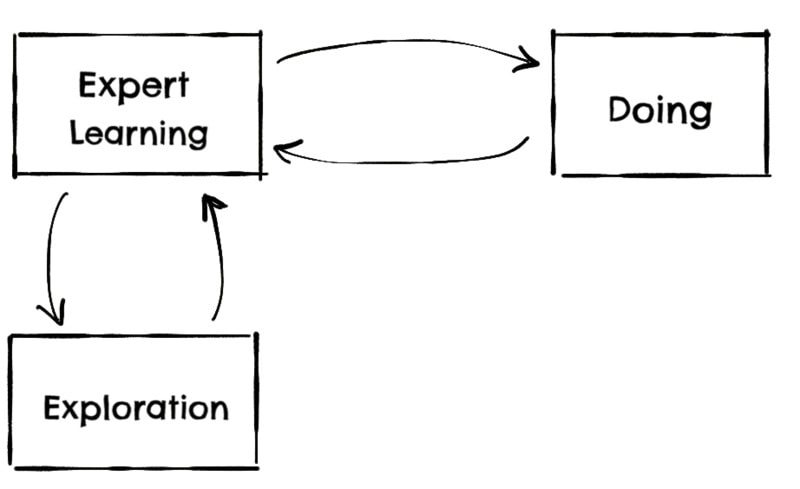
This exploration phase requires you to read loads of documentation, dig into databases, investigate third-party APIs, mix and match internal services, and sniff into your event queues.
And a REPL is the best tool for this.
Unfamiliar libraries and frameworks
Another area where you cannot jump into TDD is when you are using some library for the first time, or when using some part of a library that you are not exactly sure how it behaves.
For a long time, I used to write “assertion-less tests” with little pieces of code to exercise the library that I wanted to learn about and then set debugging breakpoints to inspect the data that was coming in and out or peak into the state of the system.
I would write dozens and dozens of those “exploratory” examples until I was confident enough to start doing. But as I was doing, I would need to go back to this technique when my knowledge of the library would falter again, moving from doing to exploring several times per day:
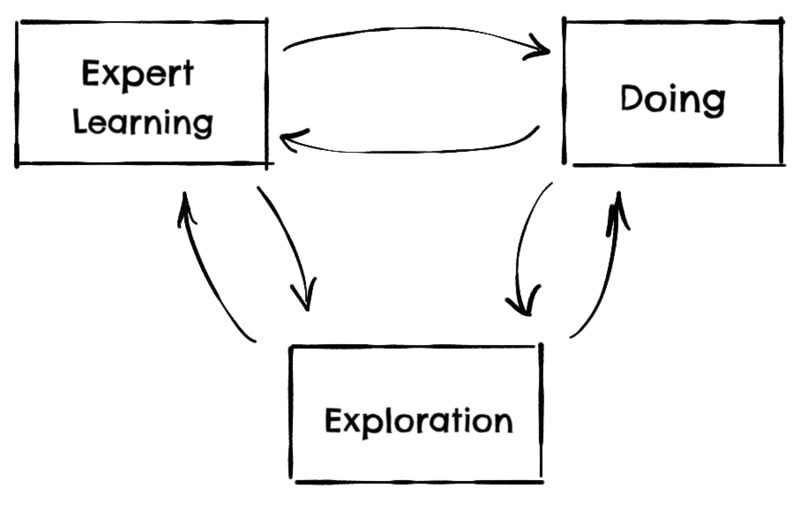
I wrote that exploratory code in the form of tests for no other reason than the IDE made it very easy to run them.
And a REPL is the best tool for this.
Side effects
Side effects make it very obvious all of our testing efforts are based on lies.
Mocks, stubs, fakes, spies: all lies to make our testing feedback loop robust and fast.
All types of testing are based on lies. Some lies are more truthful than others, but your unit tests are a lie, your TEST environment is a big lie, your performance tests are a lie. The only real testing is actual users bashing your production system, but we call this type of testing "monitoring".
The best thing is to avoid lies altogether. Why mock a database if running a local database can be robust and fast enough for your testing?
A lot of times this is not practical so we are forced to write those lies to keep our sanity.
To make our lies truthful, you need to understand pretty well the behavior of both the external system and the libraries that we will use to interact with them.
For this, we need to go back to the exploration phase, where we write lots of little programs to exercise the external system, to understand its behavior and misbehavior so that we fill up our knowledge and convert those unknown side effects into known side effects that we are confident enough to mock, fake or stub.
And a REPL is the best tool for this.
This is why testing the frontend is so damn difficult. The side effect of the frontend is painting pixels on a screen and, no matter how many years of experience you have, this is a side effect that will never become a known side effect with so many screen sizes, browsers, and all their quirks.
What is a REPL?
Is like a command-line shell but using your production language.
It is like a Google DevTools console but within your IDE.
It is like an all-powerful debugger in your production environment.
It is like having a fluid conversation with your application, without any interruptions.
Not any REPL but a good REPL.
As not all REPL are born the same, you can read what to makes a good REPL good, but I have a very simple test:
You have a good REPL if you write all your code (exploratory, proof of concepts, one-off scripts, tests, and production) using a REPL.
Note that I said “using” a REPL and not “in” the REPL, which is an important distinction and what sets good REPLs apart.
A REPL for exploring new business logic.
A REPL allows for your exploration to be done in the most efficient way: by writing little programs using a Turing complete language.
And not any language, but your production language, the one you are the most familiar with, that makes you the most efficient, that you can use from your awesome IDE, and has all those libraries to connect to, dig into and inspect any data source.
A REPL for exploring unfamiliar libraries.
To learn about unfamiliar libraries, you need to read their docs and write loads and loads of experiments.
As James Ward puts it:
Programming, no matter what level, is mostly trial & error. So before anything else, optimize for the shortest feedback loop possible.
With a REPL, the feedback loop is immediate: there is no build, compilation, deploy, or start-up delay.
Compared with a script, a REPL allows you just chose which bits of the application or experiment you want to re-run, which makes it easier focus, instead of having to run a whole script all the time.
Once you get used to this feedback loop, even delays of a couple of seconds feel like “living with lag”. You want to have a conversation with your application, not one of those Skype conversations.
A REPL for exploring side effects.
It is quite usual to use specific tools to explore databases and other external systems, but those tools do not compose.
By using a REPL, you can again use a full Turing complete language and mix and max data from any system.
As a big plus, the side effect of exploring side effects with a REPL is production code ready to be used, and data samples for your TDD workflow.
A REPL for doing.
The immediate feedback loop is not only extremely useful during the exploration phase, but also for doing.
And the most important, with a REPL you are carving your application from inside it, building it from zero without ever having to stop it, adding functionality in baby steps.
As we are constantly moving between doing and learning, using the same tool for both doing and learning removes the friction of switching between tools and makes the feedback loop way faster.
If you want to learn more about the REPL, maybe you want to watch my talk about it or Stuart Halloway’s REPL Driven Development.
More about efficiency:
- Disable notifications
- Master your IDE
- Write programs for yourself
- Why to Docker Compose a calm environment
- Did you read my email?
- Go and have a rest
- The conference talk
- Other reasons for TDD: Baby steps, ROI, Evil Manager Syndrome and Watching the watchmen
- Where TDD falls short, find yourself a good REPL (you are here)