The self-inflicted denial-of-service (DDoS) attack
Reviewing a pull request has bring back "fond" memories of an outage from a previous life.

I was happily complaining reviewing some pull request, when the following piece of code make me shudder:
var unsent-messages = new List();
function log(message) {
unsent-message =+ message
}
every (5 secs) {
send-all(unsent-messages)
unsent-message = new List();
}
Then it made me smile. I had seen a similar piece of code cause a major outage on a billion dollar company.
Outage 1
As all good outages, it all started with some network misconfiguration.
In this case, the network issue made all the company’s systems unreachable from the outside, causing a few minutes outage.
Change was reverted, service was restored, blame was assigned, bureaucracy was added and we all went back to work.
At least for some minutes.
Outage 2
A side effect of fixing the first outage was that in few seconds, like a thundering herd, thousands of our client’s browsers were trying to reconnect to back.
All services hold their ground except for one: the browser statistics service.
The Browser Statistics Service (stats service)
The stats service was born to collect feature usage data for one team, for one particular subset of the web application.
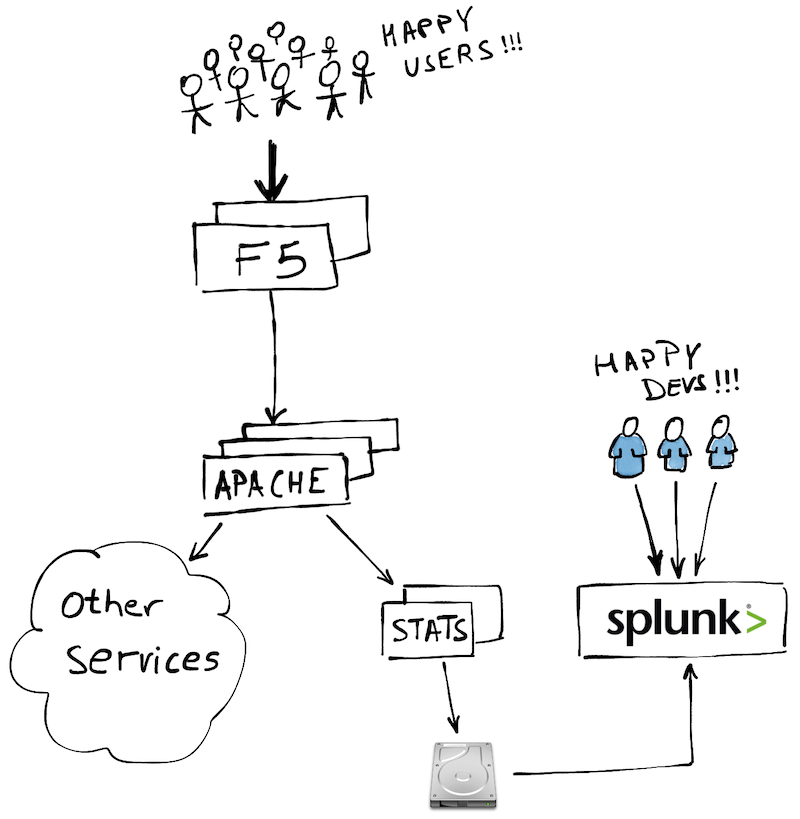
The service log into disk the usage data sent by the browser, Splunk read the log files, and the developers build in Splunk their dashboards and alerts.
It was all self-service and very low bureaucracy friction, which meant that all front-end teams ended up adopting it.
Obviously, no stats is complete without knowing how times something fails (aka. exceptions) and in what way (aka. stacktrace).
And here is where trouble started.
A big pile of errors
During the first outage, as none of the backend services were reachable, the client’s browsers have been collecting the stats of all failed attempts.
When the first outage was fixed, for the stats service was like:

The service could not write fast enough to disk, so requests started to pile up in the stats service.
The piled up requests increased the memory pressure, causing the stats service to GC like crazy, adding yet more latency.
When the Apaches noticed that an stats service instance was not timely responding, they did the opposite of what you would like: they resent the requests to another instance, basically doubling the pressure.
And, as all these request started to fail or timeout, the client’s browser diligently recorded the failure and added it to the pile of errors to report.
DDoS attack
To add salt to the injury, the front-end stats library had been designed to not lose data, hence a failed request to the stats service would not reset the stats.
In fact, the failed stats requests would be recorded and added to the next stats service call, which made the stats message size bigger and bigger, adding more and more pressure to the already struggling stats service and everything on its path.
The amount of traffic caused the Apache layer to start choking, making requests to other downstream services slower and slower.
This raised the number of errors in the client’s browsers, which increased the stats request’s size even further, which caused the Apaches to choke even more, which added extra latency, causing more errors, bigger requests, more latency, more errors, …

End result: thousands of browsers all over the globe sending every few seconds megabyte long POST requests to the stats service, telling the stats service that the stats service - and everything else - was failing.
A complete outage thanks to a self-inflicted distributed denial-of-service attack.
Steady State pattern
Multiple things went wrong (and multiple things we fixed afterwards).
Focusing on the initial piece of code, applying the Steady State pattern could have avoided the issue.
Steady State just points out the obvious: nothing is infinite. Not memory, not CPU, not bandwidth, not disk, not time, not money.
So you need to set some limits: the max size in the unsent messages array in this case.
Adding those limits is scary, mostly because the fear of missing out.
But without those limits, your system’s stability is at risk, specially when things start to fail.
And remember that …
