Apache Http Client and Asynchronous HTTP client timeouts explained in pictures
Explaining with pictures what connection timeout, read timeout and connection pool timeout are, and how Apache HTTP Client compares to Asynchronous HTTP client when handling them
I recently had to introduce a colleague to the wonderful and exciting world of timeouts in Apache HttpClient. As the usual explanation that “the connection timeout is the maximum time to establish a connection to the server” is not the most descriptive one, let’s try to explain with a couple of pictures what each timeout actually means.
Even if we will be talking about Apache’s HttpClient, the following explanation is useful for any TCP based communication, which includes most of the JDBC drivers.
As a reference, here are all the timeouts that you must configure if you want a healthy production service:
- Connection Timeout
- Read Timeout
If you are using microservices, you will also need to configure a connection pool and the following timeouts:
- Connection Pool Timeout
- Connection Pool Time To Live (TTL)
You will find here how to configure these timeout outs in Java. In our examples we will use clj-http which is a simple wrapper over Apache’s HttpClient. We will also compare how timeouts work in Asynchronous HTTP Client.
All the code, including a docker compose environment to test the settings can be found at https://github.com/dlebrero/apache-httpclient-timeouts.
Connection timeout
Before your http client can start interchanging information with the server, a communication path (or road or pipe) between the two must be established.
This is done with a handshake:

After this interchange you and your partner can start a conversation, that is, exchange data.
In TCP terms, this is called the 3 way handshake:

The connection timeout controls how long are you willing for this handshake to take.
Let’s test it using a non-routable IP address:
;; Without connection timeout
(time
(try
(client/get "http://10.255.255.1:22220/")
(catch Exception e)))
"Elapsed time: 75194.7148 msecs"
;; With connection timeout
(time
(try
(client/get "http://10.255.255.1:22220/"
{:connection-timeout 2000})
(catch Exception e
(log/info (.getClass e) ":" (.getMessage e)))))
"Elapsed time: 2021.1883 msecs"
INFO a.http-client - java.net.SocketTimeoutException : connect timed out
Notice the different elapsed time, the exception printed and the message within the exception.
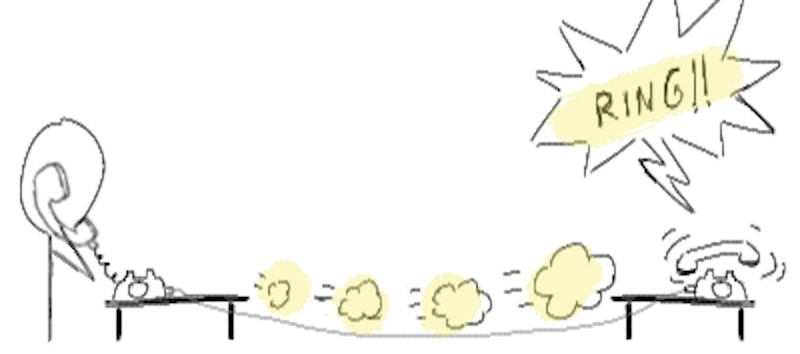
Read timeout
Once the connection is established, and you are happily talking with the server, you can specify how long you are willing to wait to hear back from the server, using the read timeout:

Let’s test it, using this time around an Nginx server, with a Toxiproxy in the middle to mess around with the response times:
;; With no socket timeout
(time
(try
(client/get "http://local.toxiproxy:22220/")
(catch Exception e (.printStackTrace e))))
"Elapsed time: 240146.6273 msecs"
;; Same url, with socket timeout
(time
(try
(client/get "http://local.toxiproxy:22220/"
{:socket-timeout 2000})
(catch Exception e
(log/info (.getClass e) ":" (.getMessage e)))))
"Elapsed time: 2017.7835 msecs"
INFO a.http-client - java.net.SocketTimeoutException : Read timed out
Note that the default socket timeout is system dependant. Notice the different elapsed time, the exception printed and the message within the exception.
The ToxiProxy configuration can be found here.
Pub quiz
With these two timeouts, you should easily score one point for your team on your next IT Pub Quiz Championship:
If you configure your HTTP client with a 10 seconds connection timeout and a 1 second read timeout, how long is a thread going to get stuck after issuing an HTTP request, in the worst case scenario?
You guess it right! Infinite! One point for your team!
Whoot? You did not answer infinite? It is soooo obvious (sarcasm).
Let’s again call one of your friends and ask him about Pi, but this time we are going to call one of those high precision smartass friends:

What is going on?
If you read carefully the previous explanation about the read timeout or even better, the javadoc about it you will notice that the read timeout is reset each time we hear from the server, so if the response is too big, the connection is too slow, the server is choking, or anything between the client and the server is having trouble, your client thread will be there hanging for a very long time.
Let’s see it in action. First we configure Toxiproxy to be very very slow while proxying the Nginx response (~ 2 bytes per second):
(client/post "http://local.toxiproxy:8474/proxies/proxied.nginx/toxics"
{:form-params {:attributes {:delay 1000000
:size_variation 1
:average_size 2}
:toxicity 1.0
:stream "downstream"
:type "slicer"}
:content-type :json})
And now we make exactly the same request as before, with a two seconds timeout:
(time
(try
(client/get "http://local.toxiproxy:22220/"
{:socket-timeout 2000})
(catch Exception e
(log/info (.getClass e) ":" (.getMessage e)))))
"Elapsed time: 310611.8366 msecs"
That is more than five minutes! And thankfully it is just 600 bytes.
Here is how the HttpClient logs look like, for just reading the first bytes of the header:

That looks pretty slow. Of course, this will never ever happen to you (more sarcasm here).
We will see at the bottom how to avoid this issue.
Connection Pool
Before talking about what the connection pool timeout is, let’s see what is the point about having a connection pool with an example.
Let’s say that there are two Stock Market traders with a special interest in Mordor Stocks (Symbol: M$). Both are watching the same news channel, but one is using a connection pool (the one on the right) while the other is not:

As you can see, the trader with the connection pool leaves the phone off the hook and the broker waiting for more orders.
When, quite unexpectedly, a one metre humanoid manages to travel 2900 km across several war zones and inhospitable areas, and deliver the only existing nuke to the only existing weak spot of Sauron, the trader can very quickly sell all of his Mordor Stocks, while the trader without the connection pool is doomed.
So if you are going to call the same server a lot, which is typical for microservices architectures, you will want to avoid the overhead of creating new connections to the server, as it can be quite an expensive operation (from a few millis to hundreds of millis).
This is especially true if you are using HTTPS. See the TLS handshake.
Connection pool timeout and TTL
As much as connection pools are awesome, as with any other resource, you need to limit the maximum number of open connections that you want to maintain, which means that there are three possible scenarios when fetching a connection from the pool.
Side note: for a very good talk about how to size your connection pool see “Stop Rate Limiting! Capacity Management Done Right” by Jon Moore.
Scenario 1. Free connections.
Assuming a max connection pool of three, the first scenario is:

So there is some phone available but on the hook. You will need to suffer the extra connection setup delay.
Scenario 2. Connection pooled.
The second scenario:

There is a phone off the hook, ready to be used. In this scenario, there are another two cases:
- The connection is fresh, created less than the configured TTL. You will NOT need to suffer the extra connection setup delay.
- The connection is stale, created more than the configured TTL. You will need to suffer the extra connection setup delay.
Let’s test it:
;; Create a new connection pool, with a TTL of one second:
(def cp (conn-manager/make-reusable-conn-manager
{:timeout 1 ; in seconds. This is called TimeToLive in PoolingHttpClientConnectionManager
}))
;; Make ten calls, two per second:
(dotimes [_ 10]
(log/info "Send Http request")
(client/get "http://local.nginx/" {:connection-manager cp})
(Thread/sleep 500))
Looking at the logs:
16:56:24.905 INFO - Send Http request
16:56:24.914 DEBUG - Connection established 172.24.0.4:51984<->172.24.0.2:80
16:56:25.416 INFO - Send Http request
16:56:25.926 INFO - Send Http request
16:56:25.933 DEBUG - Connection established 172.24.0.4:51986<->172.24.0.2:80
16:56:26.434 INFO - Send Http request
16:56:26.942 INFO - Send Http request
16:56:26.950 DEBUG - Connection established 172.24.0.4:51988<->172.24.0.2:80
16:56:27.452 INFO - Send Http request
16:56:27.960 INFO - Send Http request
16:56:27.967 DEBUG - Connection established 172.24.0.4:51990<->172.24.0.2:80
16:56:28.468 INFO - Send Http request
As expected, we can make two requests before recreating the connection.
Same scenario but with a 20 seconds TTL:
16:59:19.562 INFO - Send Http request
16:59:19.570 DEBUG - Connection established 172.24.0.4:51998<->172.24.0.2:80
16:59:20.073 INFO - Send Http request
16:59:20.580 INFO - Send Http request
16:59:21.086 INFO - Send Http request
16:59:21.593 INFO - Send Http request
16:59:22.100 INFO - Send Http request
16:59:22.607 INFO - Send Http request
16:59:23.114 INFO - Send Http request
16:59:23.623 INFO - Send Http request
16:59:24.134 INFO - Send Http request
So the same connection is used for all requests.
But why do we need the TTL? Mostly because firewalls have this tendency on dropping long live connections (especially idle ones) without telling any of the involved parts, which causes the client to take a while to realize that the connection is no longer usable.
Scenario 3. All connections in use.
The last scenario:

All the phones are busy, so you will have to wait. How much you are willing to wait for a phone to become free is the connection pool timeout.
Note that if a phone becomes available before the connection pool timeout, you are back to the second scenario. With some unlucky timing, you will also need to establish a new fresh connection.
Let’s look at an example. First we make the Nginx very slow, taking up to 20 seconds to respond.
Then we create a connection pool with a maximum of three connections and we send four HTTP requests:
(def cp-3 (conn-manager/make-reusable-conn-manager
{:timeout 100
:threads 3 ;; Max connections in the pool.
:default-per-route 3 ;; Max connections per route (~ max connection to a server)
}))
(dotimes [_ 4]
(future
(time
(client/get "http://local.toxiproxy:22220/" {:connection-manager cp-3}))))
"Elapsed time: 20017.1325 msecs"
"Elapsed time: 20016.9246 msecs"
"Elapsed time: 20020.9474 msecs"
"Elapsed time: 40024.5604 msecs"
As you can see, the last request takes 40 seconds, 20 of which are spent waiting for a connection to be available.
Adding a one second connection pool timeout:
(dotimes [_ 4]
(future
(time
(try
(client/get "http://local.toxiproxy:22220/"
{:connection-manager cp-3
:connection-request-timeout 1000 ;; Connection pool timeout in millis
})
(catch Exception e
(log/info (.getClass e) ":" (.getMessage e)))))))
"Elapsed time: 1012.2696 msecs"
"2019-12-08 08:59:04.073 INFO - org.apache.http.conn.ConnectionPoolTimeoutException : Timeout waiting for connection from pool"
"Elapsed time: 20014.1366 msecs"
"Elapsed time: 20015.3828 msecs"
"Elapsed time: 20015.962 msecs"
The thread that is not able to get a connection from the pool gives up after one second, throwing a ConnectionPoolTimeoutException.
Are we done yet?
Unfortunately, even if connection timeout, read timeout, connection pool timeout and connection pool TTL are the most common things to tweak, you should also be aware of:
- DNS resolution: it cannot be explicitly configure it in Java, system dependant. Good to also know how it is cached.
- Hosts with multiple IPs: In case of a connection timeout, HTTP client will try to each of them.
- TIME_WAIT and SO_LINGER: closing a connection is not immediate and under very high load it can cause issues.
All together!
Putting all the timeouts together, we have:

With all these timeouts, it is quite a challenge to know how long a HTTP request is actually going to take, so if you have any SLA or are worried about the stability of your application, you cannot solely rely on setting the timeouts correctly.
If you want to setup just some simple timeout for the whole request, you should be using Hystrix Thread Isolation, Apache HTTP Client’s FutureRequestExecutionService (never used this one myself) or maybe use a different HTTP client.
Asynchronous HTTP Client
A possible solution to all these timeouts juggling is to use Asynchronous HTTP Client, which is based on Netty. You can see here all the above scenarios but using the Asynchronous HTTP Client.
Some notable differences between both HTTP clients:
- Asynchronous HTTP clients have their own thread pool to handle the response once it arrives.
- No connection pool timeout: if the pool is completely used, an exception is thrown. There is no waiting for a connection to be available. Interestedly, I usually configure my Apache HTTP connection pools to behave the same, as a full connection pool usually means that something is not going working and it is better to bail out early.
- Connection pool idle timeout: as we mentioned before, we wanted a connection pool TTL mostly because idle connections. Asynchronous HTTP Client comes with an explicit idle timeout, on top of a TTL timeout.
- A new request timeout: a timeout to bound the amount of time it takes to do the DNS lookup, the connection and read the whole response. One single timeout that states how long you are willing to wait for the whole HTTP conversation to be done. Sweet.
So the timeouts for the Asynchronous HTTP client look like:

You can see again all the same scenarios but using this new request timeout here, including the Pub Quiz one.
Reasoning about the worst case is a lot easier.
Summary
In summary, timeouts are annoyingly difficult to configure, if you want to have some control over the maximum time allocated for an HTTP request/response. Unless, you are using an Asynchronous HTTP Client (or probably other async clients).
Am I suggesting that you should not use Apache HTTP Client?
Well, it depends what functionality you are using. Apache HTTP Client is a very mature project with plenty of build-in functionality and hooks to customize it. It even has an async module and the newer 5.0 (beta) version comes with build-in async functionality.
In our case, after this long explanation to my colleague, given our use cases, moving to Asynchronous HTTP Client was my suggestion.