RocksDB range queries in KafkaStream: dealing with big results
An example of when to use the RocksDB range query in KafkaStreams.
There was an interesting question on the Confluence Slack channel, paraphrasing:
Hi,
I created a Kafka Streams app … where external processes put a command message on an “input.cmd” topic with a pending status, the app process it and put an updated command message on the same “input.cmd” topic with a new status indicating if it was processed with or without errors.
Now I need to create a stream app that will receive a file containing lots of commands (~100k), send each command to the existing process, read the result of the processing (the updated command) and produce a new file with the result of each line.
Is there a good way to do this without incurring in saving very big objects in the DataStore?
My problem is that I am collecting the completed messages and keeping them in the Store, but am struggling to make an efficient algorithm that would not use too much memory since the messages can come back in any order and from many files (lots of files might be still under processing).
Note that the issue here is not that the Kafka messages are too big (>1mb), but that the consuming application has to collect hundreds of thousands of small messages to produce the result.
A naive approach would mean storing in our KafkaStreams application an state object like:
{:file "a file"
:partial-results [{:line 1 :result "result1"}
{:line 110202 :result "result21"}
{:line 329323 :result "result32"}
{:line 132423 :result "result412"}
{:line 62 :result "result14234"}
{:line 33 :result "result1121132321"}
,,, ;; Hundred of thousands more here
]}
You can imagine how expensive would be to deserialize, update and serialize back the state once we have 100k lines in that array, every time a new line is processed. The object could even end up not fitting in the JVM heap.
External storage
The developer that asked the question has a very reasonable solution:
The solution I am implementing is to use Cassandra (we already use it) to keep the file ordered. Every completed message that arrive, I put the corresponding result line in this table.
So we use the capabilities of another storage database to store and later retrieve the results in the correct order.
This is probably fine, if you have Cassandra running, but what if you do not, or if you prefer to have less moving parts in your application?
RocksDB range queries
It happens that KafkaStream’s state store provides a range query, that returns all the objects stored in a StateStore between two keys.
Let’s see how we can use this API to implement an efficient way to store and retrieve big results.
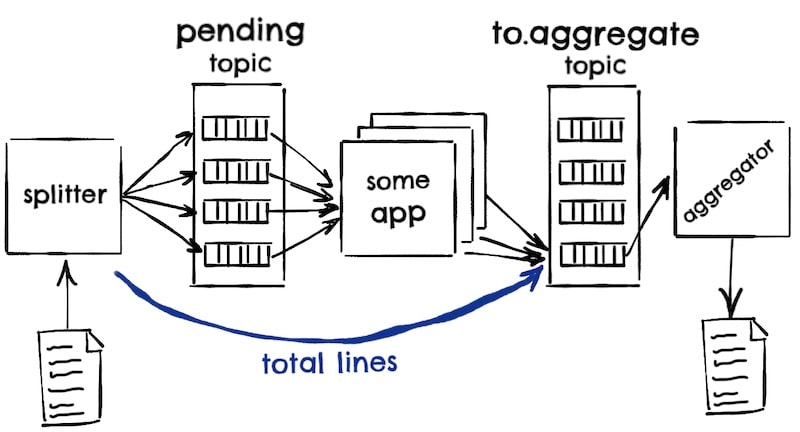
The architecture
The splitter process reads the very big file with those 100k of commands and puts each command in some pending topic. Once the splitter has finished pushing all the pending commands, it will know how many lines/commands the file had, and it will push this total lines to our aggregator’s input topic. The aggregator will use this number to know when it has received all the processed commands.
Note that the splitter will use no key when pushing to the pending topic so that the commands are evenly distributed to all partitions (more or less), but then, all the processed commands for a given file must end up in the same to.aggregate partition so that they end up being consumed by the same aggregator process. We will use the name of the file as the key, assuming is unique enough.
Given that the splitter does not know before hand the number of lines in the file, and that the commands will be processed in a semi-random order, our aggregator input could look like:
| Key | Line Number | Partial Result | Total Lines |
|---|---|---|---|
| file1 | 2 | SecondLine | |
| file1 | 3 | LastLine | |
| file1 | 3 | ||
| file1 | 1 | FirstLine |
Notice that in this case, our aggregator receives two lines before it knows that there should be a total of three, and that it receives line 1 the last.
The state
Instead of just storing one piece of state on the aggregator with all the partial results on it, what we are going to do is move the partial results out of it.
To do that, we will store each partial result with a key like:
(defn line-key [file-name line-number]
(format "%s-part-%019d" file-name line-number))
So the result for the first line will be stored with a key like thefilename-part-00000000001.
This way, once we know that our aggregator app has received all the partial results for a file, we can use the StateStore range query to retrieve all partial results by using the range thefilename-part-00000000001 to thefilename-part-00000xxxxxxx, being xxxxxx the total number of lines. In code:
(defn all-results-received [store file-id total-lines]
(log/info "Writing file " file-id "total records" total-lines)
(with-open [all-records (.range store (line-key file-id 0) (line-key file-id total-lines))
writer (io/writer file-id)]
(doseq [^KeyValue record (iterator-seq all-records)]
(.write writer (str (.key record) "->" (.value record) "\n"))))
(log/info "Deleting")
(let [all-keys (map
(fn [i] (KeyValue. (line-key file-id i) nil))
(range 1 (inc total-lines)))]
(doseq [keys-batch (partition-all 1000 all-keys)]
(.putAll store keys-batch)))
(.delete store file-id))
Remember that the iterator returned by RocksDB is lazy, so we do not need to realize the whole result in memory.
To know if we have received all the partial results, we just need to keep a count of how many we have seen so far, and compare that number with the total number of lines in the file:
(defn check-if-all-results-received [store file-id records-so-far total-lines]
(when (= records-so-far total-lines)
(all-results-received store file-id total-lines)
{:finish file-id}))
(defn get-so-far [store file-id]
(or (.get store file-id) {:so-far 0}))
(defn line-processed [store file-id {:keys [line-number partial-result]}]
(let [{:keys [total-lines so-far]} (get-so-far store file-id)
records-so-far (inc so-far)] ;; Increment counter
(.put store (line-key file-id line-number) partial-result) ;; store partial result
(.put store file-id {:total-lines total-lines :so-far records-so-far}) ;; store counter so far
(check-if-all-results-received store file-id records-so-far total-lines)))
(defn total-lines-msg-arrived [store file-id total-lines]
(let [{:keys [so-far]} (get-so-far store file-id)]
(.put store file-id {:total-lines total-lines :so-far so-far}) ;; store total results
(check-if-all-results-received store file-id so-far total-lines)))
Note that this counter must be exact, so KafkaStream’s default at-least-once semantics is not good enough in this case, we will need to configure the exactly-once semantics.
If this becomes a performance bottleneck, we can go back to at-least-once semantics and deal with any possible double count by doing a read-repair: when writing the final result file, if the number of records returned by the range is different from the expected total, discard the generated file and set the so-far counter to the correct number (the number of results returned by the range query).
A big but
Unfortunately, there is a major but on the range query documentation:
Get an iterator over a given range of keys. … No ordering guarantees are provided.
With no ordering guarantees, it means that we would need to sort the results in memory, which maybe ok, depending if the whole result fits in memory or not.
Angering your architect
If we dig a little bit on the source code of the RocksDB range implementation we find the following comment:
RocksDB’s JNI interface does not expose getters/setters that allow the comparator to be pluggable, and the default is lexicographic, so it’s safe to just force lexicographic comparator here for now.
So the actual implementation returns the results in lexicographical order, which means that it will return the partial results already ordered by line number, which is what we are looking for.
This means that, if we accept the trade-off of depending on some implementation detail, we can avoid the restriction that the result must be ordered in memory.
Pissing off your architect
But probably we are not using just a plain RocksDbStore, but one wrapped by a CachingKeyValueStore.
We could configure KafkaStreams to not use the cache, but given that we are already relying on some implementation detail … we see that the CachingKeyValueStore range implementation returns a MergedSortedCacheKeyValueBytesStoreIterator, which its next() implementation looks like:
public KeyValue<K, V> next() {
// Simplified code
final Bytes nextCacheKey = cacheIterator.peekNextKey();
final KS nextStoreKey = storeIterator.peekNextKey();
//
final int comparison = compare(nextCacheKey, nextStoreKey);
if (comparison > 0) {
return nextStoreValue(nextStoreKey);
} else if (comparison < 0) {
return nextCacheValue(nextCacheKey);
} else {
storeIterator.next();
return nextCacheValue(nextCacheKey);
}
}
So the merge expects the keys of both the cache and the actual store (the RocksDB one) to be ordered in the same way, as it is comparing them and advancing either of the iterators depending on an order.
We could conclude that, given that the RocksDB iterator uses a lexicographical order, the cache must use the same order, but, just in case, let’s looks at the MergedSortedCacheKeyValueBytesStoreIterator compare method:
public int compare(final Bytes cacheKey, final Bytes storeKey) {
return cacheKey.compareTo(storeKey);
}
The cacheKey and the storeKey are org.apache.kafka.common.utils.Bytes, which have a compareTo implementation like:
public int compareTo(Bytes that) {
return BYTES_LEXICO_COMPARATOR.compare(this.bytes, that.bytes);
}
So the CachingKeyValueStore also takes care of returning the range results in the order that we need!
If we do not mind relying on these little implementation details, we can rely on KafkaStreams state stores range queries to be able to work in an efficient way with any huge results, even those that do not fit in memory, plus we remove the the need to use any external storage, with the consequent improvement on the simplicity and availability of our application.
We all good! (Your architect may disagree about this statement and with any enthusiasm associated with it)
All the code can be found here, including a Docker Compose file that will run Kafka, Zookeeper plus three instances of this service, so you can play around with it. The details of how to build and run it are in the repository.