Documenting your architecture: Wireshark, PlantUML and a REPL to glue them all.
Instead of drawing UML diagrams, why not generate them from a network traffic capture of the running system?
I recently had to document the results of the evaluation of a new system.
The proof of concept for the system included six possible configurations, each option having a significant architectural impact on the system.
To understand all six, I have been squinting at the logs from the servers plus the Chrome DevTools network panel, trying to correlate the requests with the responses and the traffic between the servers.
As part of the documentation I thought it would be important to have some sequence diagrams to explain the protocol between the different parts of the system.
But when trying to draw the sequence diagrams, I realized that all that squinting had just allowed me to grasp the general feeling of the difference between the options, but not enough to write down a proper and accurate description of each one.
Also, the prospective boredom of opening my least hated UML tool and spending some hours dragging and dropping boxes and fiddling around with lines, didn’t fill me with joy.
Given that I already had the six combinations running for the proof of concept, couldn’t I leverage on that?
The tools
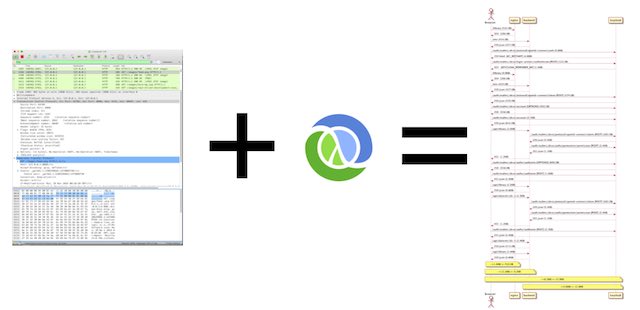
First, we need to find out all the traffic between the components of the system. For this we will use the venerable Wireshark.
Wireshark will allow us to capture any network traffic, filtering out anything unnecessary, plus it comes with a handy export to json feature to simplify the parsing of the output.
A snippet of what a HTTP request looks like:

Second, we will need to generate the UML diagrams. For this we will use PlantUML, which is a text based UML DSL with the accompanying libraries to generate images. Being text based, our problem of generating UML diagrams becomes one of string concatenation.
Lastly, we need some glue to transform the Wireshark json files to PlantUML text files. We will use Clojure but any turing complete language would do. Of course, a Clojure REPL makes the task more pleasant.
The result
First, to show off, lets look at how one of the diagrams looks like:

This diagram requires 40 lines of PlantUML that look like:
browser -> backend: /api/datasets/ds-1 (536.0B)
browser <-- backend: 200 json (0.7KB)
browser -> backend: /api/library (525.0B)
browser <-- backend: 200 json (1.0KB)
note over browser, nginx: ->1.2KB/<-532.0B
note over browser, backend: ->4.4KB/<-5.3KB
The whole PlantUML code is here and the code can be found here.
If you are curious, the diagram corresponds to loading a Single-page application, doing authentication with OpenID Connect and authorizing an API endpoint with User-Managed Access.
Benefits
The benefits of using these three tools are:
- We are able to generate a set of diagrams that are accurate, giving you the confidence that you are not missing anything. Assuming no bugs in the parsing code .
- As the set of diagrams are generated using the same code, they all look consistent, both in the data that they contain and in their look and feel.
- The data, the diagrams and the code to generate them are all text, which means that can be version control and manually inspected or tweaked if required.
- If we decide to change any details about the diagrams, it will take no time to update all diagrams.
- Maybe the code to generate the diagrams can be used in other projects.
- The diagrams have the desired level of detail. For example, in the diagrams we have removed the loading of images, css and javascript files.
- You can add a great deal of detail to the diagrams, as the data capture has even the request/response, so you could parse them and extract the information that was relevant to your system.
- You can do all from your favourite IDE in an interactive fashion:
Drawbacks
Of course there are some drawbacks:
- We have to have the system working and we have to be able to sniff the traffic.
- The data capture can be huge, so some pre-filtering during the capture phase maybe necessary.
- There can be sensitive data in the capture. Be careful with the security!
More benefits!
Last, but probably the most important benefit, is that we have converted a tedious task into an enjoyable one.
I never thought I would say this but … Happy documenting!