Joins on stateful stream processing using Kafka Streams' KTables and GlobalKTables
Exploring different options in Kafka Streams to join KTables, both with and without shared keys.
KafkaStreams comes with a nice set of APIs that allow one to join both KStreams and KTables.
For example, in the previous article, we generated a KTable with a list of clients that we wanted to email. This KTable looked like:
| Client (Key) | positions |
|---|---|
| client1 | #{1, 3} |
| client2 | #{4} |
But we also need some of the client’s personal details, like their name, to be able to address them properly on the email. This data would be in another KTable with the current client details, like:
| Client (Key) | name | surname | |
|---|---|---|---|
| client1 | Peter | Parker | peter.parker @ dailybugle.com |
| client2 | Peter | Pan | peter.pan @ neverland.com |
So we would want to do the equivalent to:
select client_data.email from positions, client_data where positions.key = client_data.key
Which using the Kafka Streams API is like:
(->
(.join us-share-holders client-data
(k/val-joiner [positions client-data] (:email client-data)))
(.through "final-result" "final-result-store"))
The API is nice and simple, but it has two constraints:
- Both KTables must have the same key.
- Both KTables must have the same number of partitions (this is called co-partitioned).
Fixing the second issue is simple as it is just a matter of copying the Kafka topic to another Kafka topic with the correct number of partitions.
Joining KTables on a different key
One of the main reasons to join two tables on a different key is to add some kind of reference or lookup data.
Staying with the example of the previous article, we had a KTable with positions data such as:
| PositionId (Key) | Client | Ticker | Amount | Exchange |
|---|---|---|---|---|
| 1 | client1 | AAPL | 100 | NASDAQ |
| 2 | client1 | VOD | 5 | LON |
| 3 | client1 | FB | 33 | NASDAQ |
| 4 | client2 | AAPL | 25 | NASDAQ |
| 5 | client3 | VOD | 33 | LON |
To make things simpler, we assumed that the position already had the exchange of the stock, but in reality we would have another KTable with all the data related to the ticker, like the exchange, name, founded date, …
So the position data would really look like:
| PositionId (Key) | Client | Ticker | Amount |
|---|---|---|---|
| 1 | client1 | AAPL | 100 |
| 2 | client1 | VOD | 5 |
| 3 | client1 | FB | 33 |
| 4 | client2 | AAPL | 25 |
| 5 | client3 | VOD | 33 |
And the ticker KTable something like:
| Ticker (Key) | Exchange | Name | Founded Date |
|---|---|---|---|
| AAPL | NASDAQ | Apple Inc | 1976 |
| VOD | LON | Vodafone Plc | 1991 |
| FB | NASDAQ | Facebook Inc | 2004 |
To join both KTables, we would need the equivalent of:
select * from positions, tickers where positions.ticker = tickers.key
With Kafka Streams we have two options, depending on how big the smallest of the KTables we want to join is.
Option 1: Local join with GlobalKTables
Most of the time, the reference data is small enough to fit in memory or disk, so it is more efficient to have a copy of the reference data on each node instead of doing a distributed join, as doing a distributed join will require shuffling data across the network.
From Kafka 0.10.2.0, Kafka Streams comes with the concept of a GlobalKTable, which is exactly this, a KTable where each node in the Kafka Stream topology has a complete copy of the reference data, so joins are done locally.
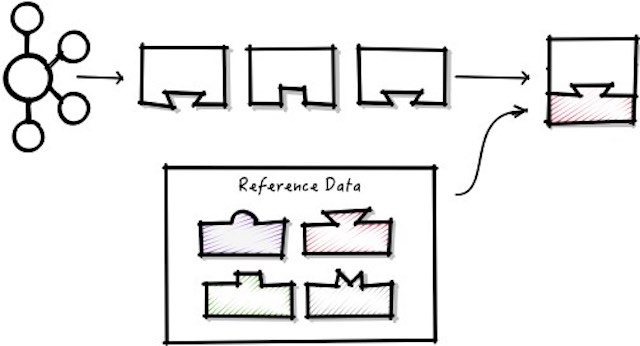
Before we look at the diagram for this option, let’s explain the legend that we are going to use.
We are going to represent the ticker reference data as a brush stroke of a particular color. For example, APPL will be  , while VOD will be
, while VOD will be  .
.
We are going to represent each raw position, that is, a position without the ticker reference data, as a colored empty shape. The color of the shape will correspond with the ticker color. For example, position 1 is for APPL, so we will represented it as ![]() , while position 2 that is for VOD will be represented as
, while position 2 that is for VOD will be represented as ![]() .
.
The results of joining the position with the ticker reference data will be the shape filled. For example position 1 after the join will become  and position 2 will be
and position 2 will be  .
.
We will also show in the diagram the required Kafka topics. The topics will be either partitioned by shape, so all star-like positions go to one partition while all triangle-like positions go to another one; or by color, so all shades of red will go to one partition while all shades of purple will go to another.
The diagram shows what was processed from one instant to the next, using a trail to easily follow the flow of positions and ticker reference data through the system.
So a GlobalKTable diagram will look like:

Note how on T0->T1, Kafka Streams will take care of reading all the reference data before starting doing any processing.
On T1->T2, we have removed the reference data topic from the diagram to make it simpler.
As both nodes have all colours, there is no need to shuffle data around.
Unfortunately KTable to GlobalKTable joins are not yet supported, it will come in Kafka 0.11.0.0 (or once this ticket is done).
Option 2: Distributed left outer join
But what if the KTables that you want to join are huge?
There is already some discussion to include this feature in a future Kafka Streams version, but until that is available, lets see how we can implement a distributed, real time, fault tolerant join using the available Kafka Streams API.
To start with, we will need to repartition one of the KTables so both topics are keyed by the same attribute. This way the rows that we need to join will end up in the same node.

Note how each of the colouring tasks has half of the colours and notice also that we now need an additional Kafka topic to hold the repartitioned data.
It is worth mentioning that on T0->T1, we are relying on Kafka Stream’s flow control to initialize the reference data before processing messages. This flow control tries to process older records before new ones, but as noted in the Kafka Stream’s documentation this is on a best-effort basis, which is a weaker guarantee than what the GlobalKTable’s one, but it seems to work pretty well.
But what if a row is deleted? At first it seems logical that we just want to send that delete straight to the result topic, as we don’t need to join anything.
The problem with this is option is that we can end up with a race condition, as the delete can outrace the new record to the result topic:

To fix this, we must make sure that we honour the order on which the messages arrive. One way of achieving it is by relying on Kafka’s per partition ordering semantics and send the deletes to the node that is doing the join and for that node to forward the delete to the resulting topic:

Notice that in the diagram we have added a local storage on the repartitioning task. Remember that in Kafka, delete messages have a null payload, so to be able to send the delete to the correct partition, we need to remember what was the previous value, so that we are able to calculate to which partition we need to send the delete.
That would fix the race condition when processing deletes, but don’t we have a similar race condition if the join key changes?

Unfortunately, for this race condition we cannot rely on the order of the processing, as each update is going to a different node.
A possible solution is to add an additional step after the join where we remember the timestamp of the last processed message for a given key, and we filter out any messages that older than it:

But this bring us again to what happens with deletes, as if we are not careful, we can end up with the following race condition:

To fix this issue, we need to remember that we deleted the row, but obviously we don’t want to remember all the rows that we ever deleted, as it will require an infinite amount of memory/disk, which means that the filtering task will need some kind of clean up process.
Are we done yet?
Well, this solution does not cater for changes and deletions on the KTable with the reference data, but this post is already long enough and it is not a simple problem.
The code and solution that I present leave me with the same kind of feeling that I have when doing any concurrency work. That I have forgotten something, that I am not sure it is correct and that unit testing is not going to prove otherwise.
Of course, some of the scenarios that we have explored may not apply to your domain. For example, in our case, it is not possible for a position to change the ticker, which simplifies the system.
So what have we learn?
Stateful stream processing is a breeze when your tools provide an easy and high level API to work with, but when you have to do it on your own, it is more like a minefield of possible race conditions.
You can find all the code and a complete Docker environment to play around here.